log
assets
第二节讲义_1682136737988_0
{kind=link}
{kind=link}
_-_image_1705670873910_0.png){kind=link}
_-_image_1705670919100_0.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
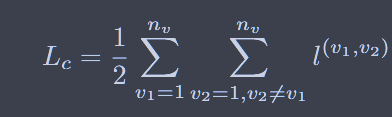{kind=link}
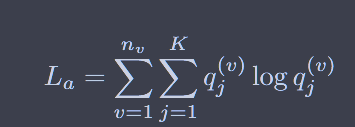{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
journals
loom
pages
static
css
{kind=link}
fonts
inter
icons
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
img
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
js
excalidraw-assets
locales
pdfjs
cmaps
tags
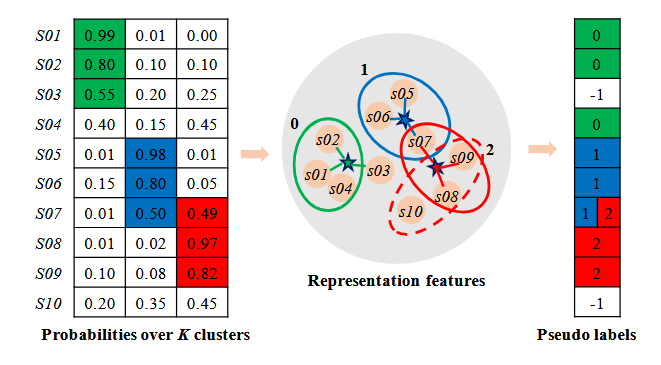
SPICE-Semantic Pseudo-Labeling for Image Clustering
一句话总结
根据kmeans等自创了一种聚类方法,挺不错的

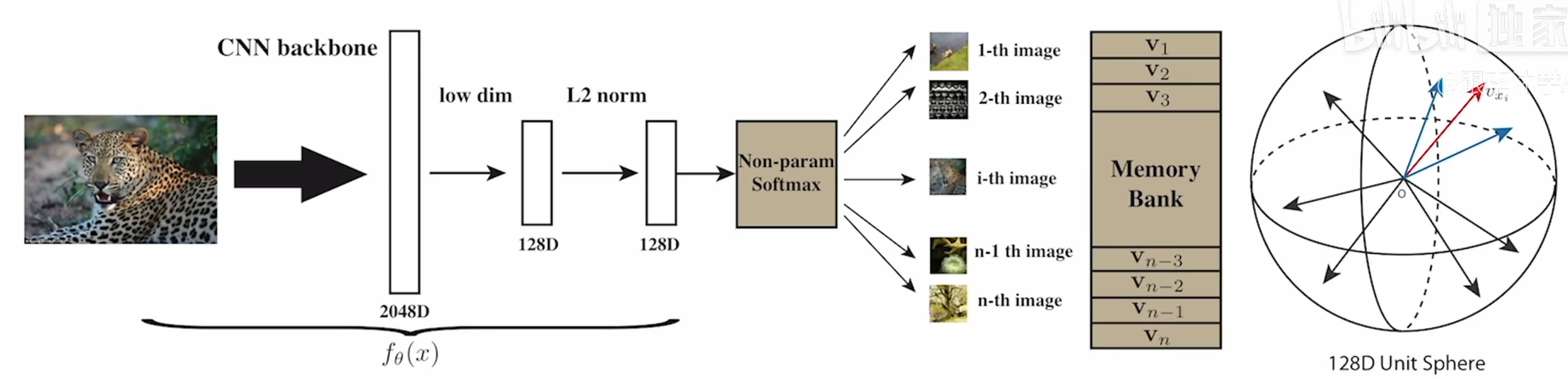
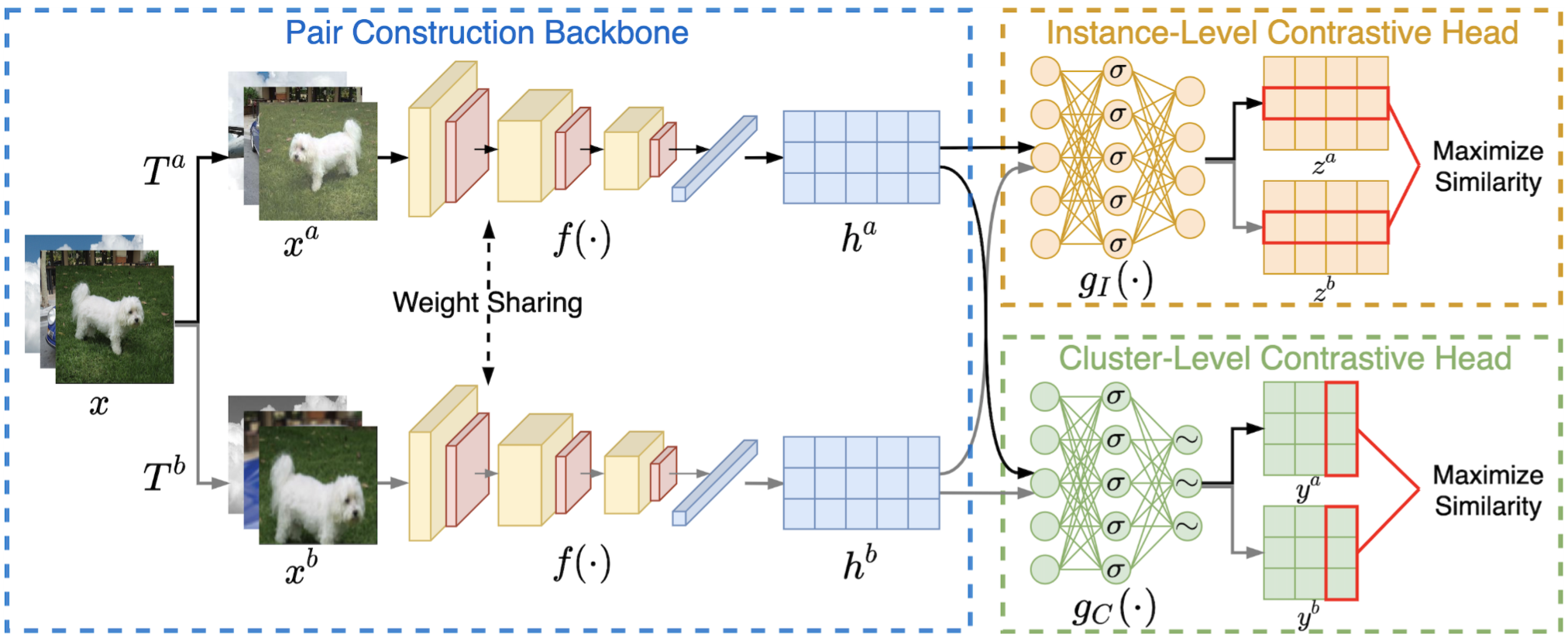
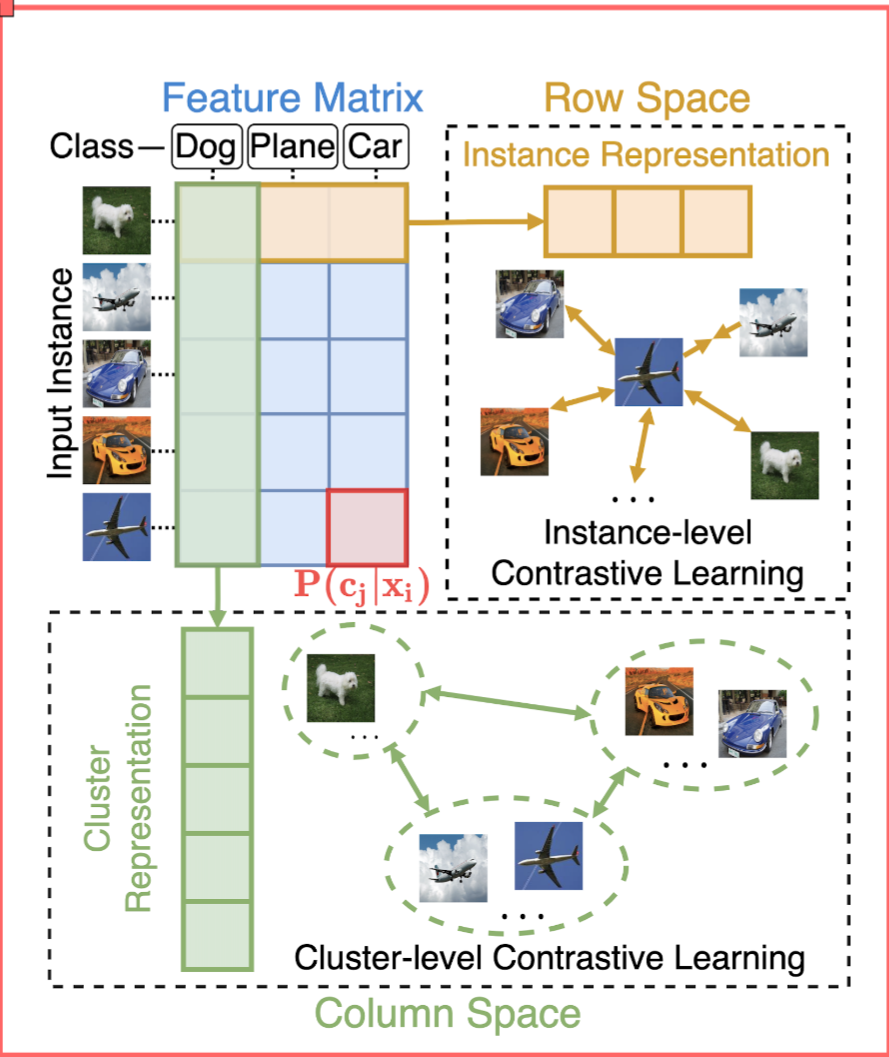
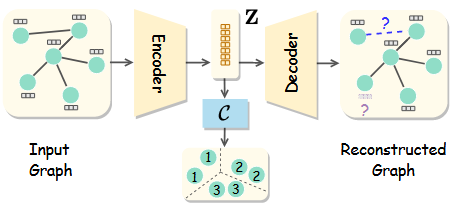
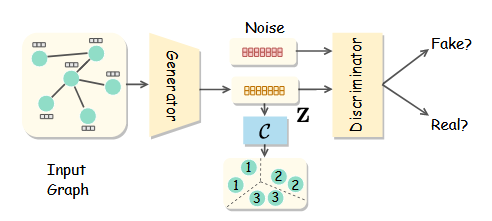
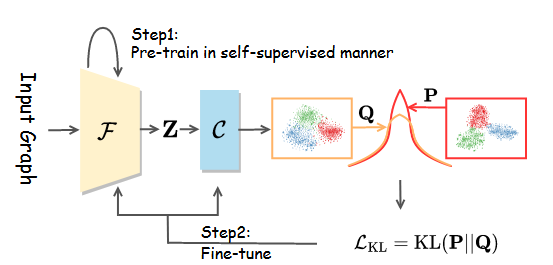
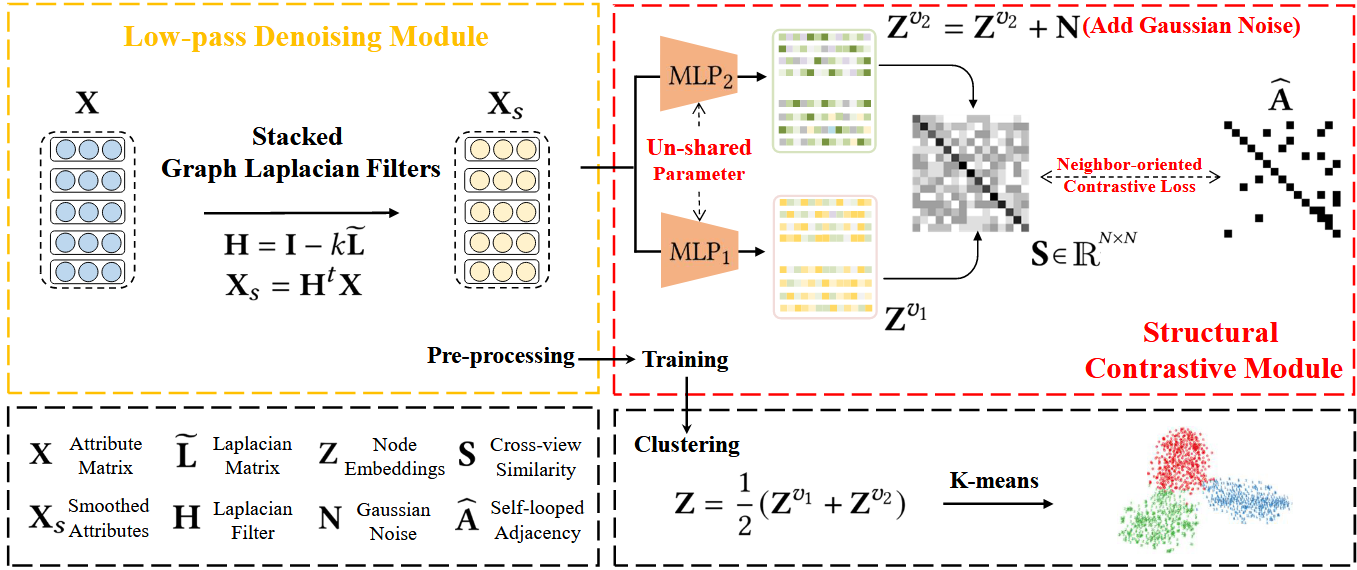
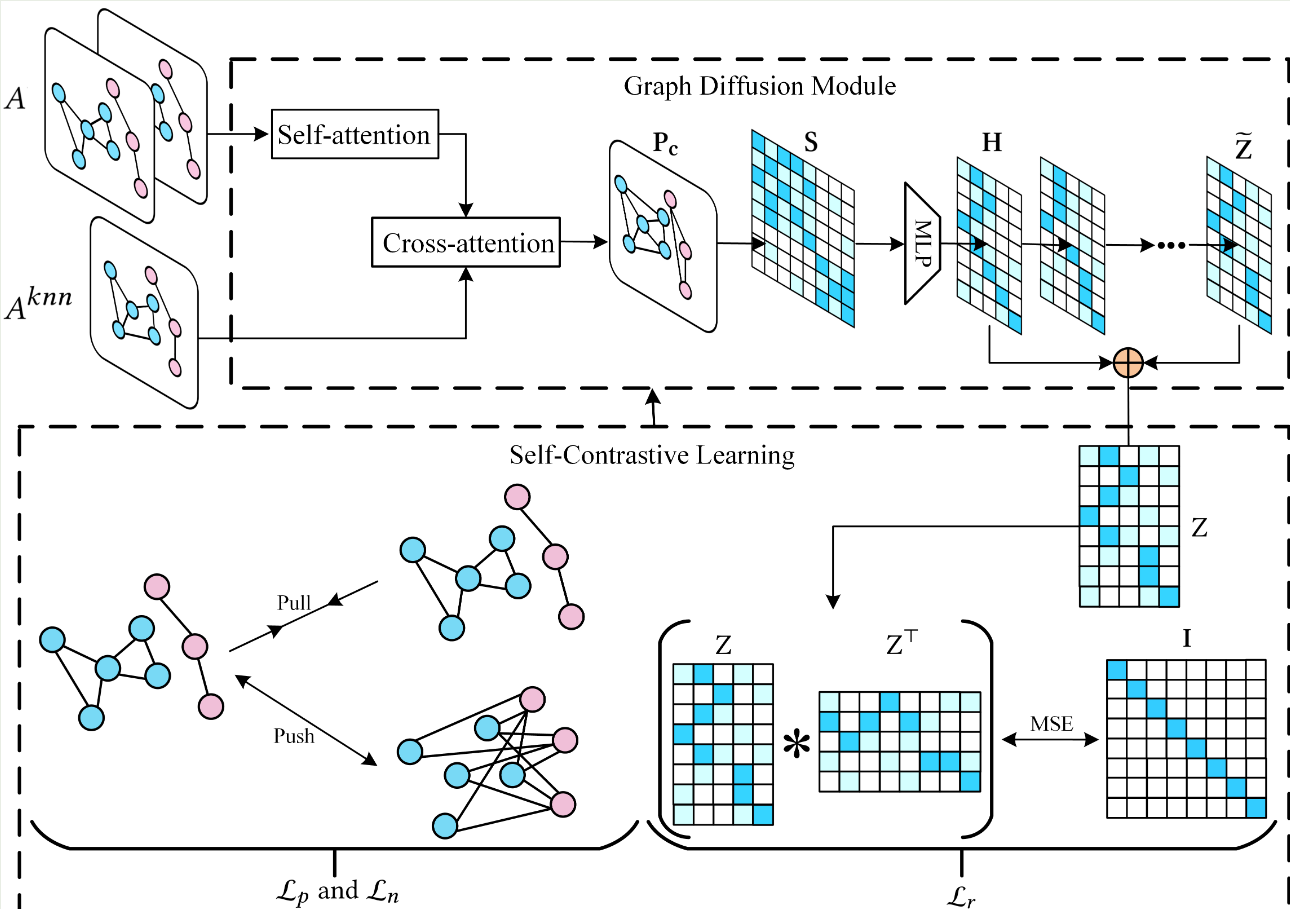
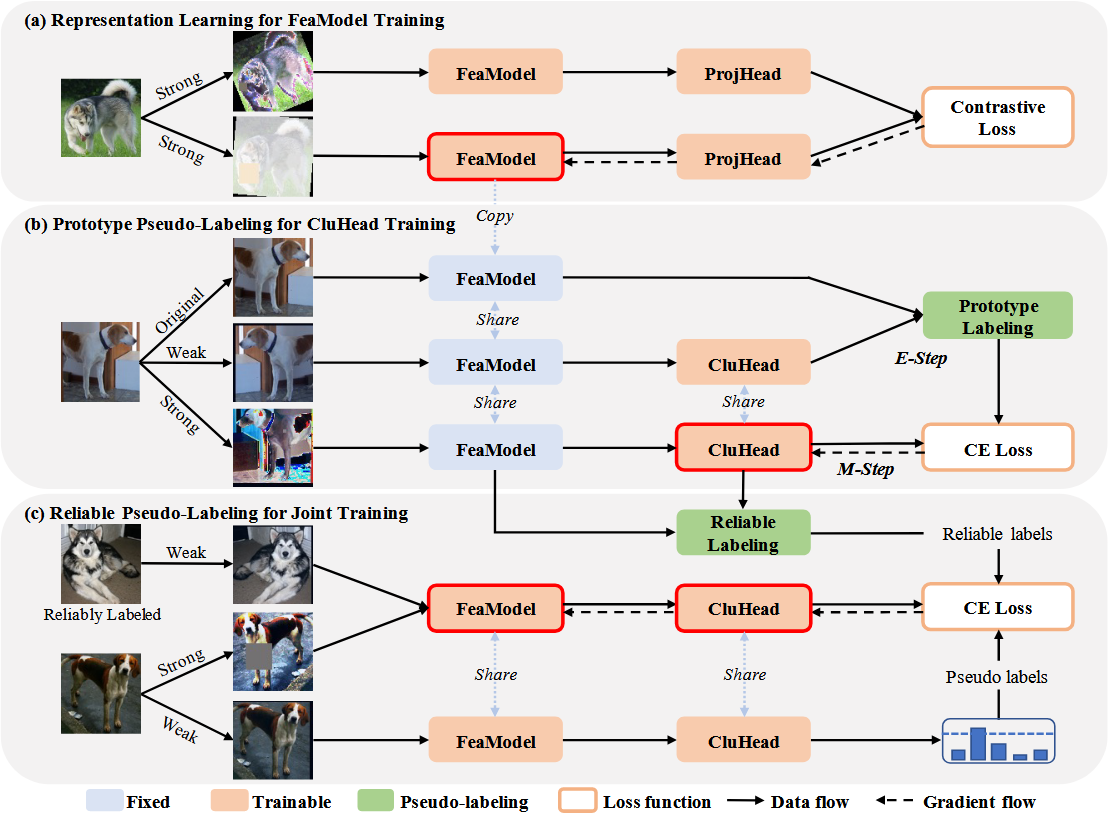
具体来说,我们将网络训练分为三个阶段,如图3所示。首先,我们通过实例级对比学习来优化特征模型F,该学习强制来自同一图像不同变换的特征相似,并且来自不同图像的特征相互区分。其次,我们用提出的原型伪标记算法优化集群头C,同时冻结在第一阶段学习的特征模型。第三,我们结合提出的可靠伪标记算法来优化特征模型和簇头。
第二部分

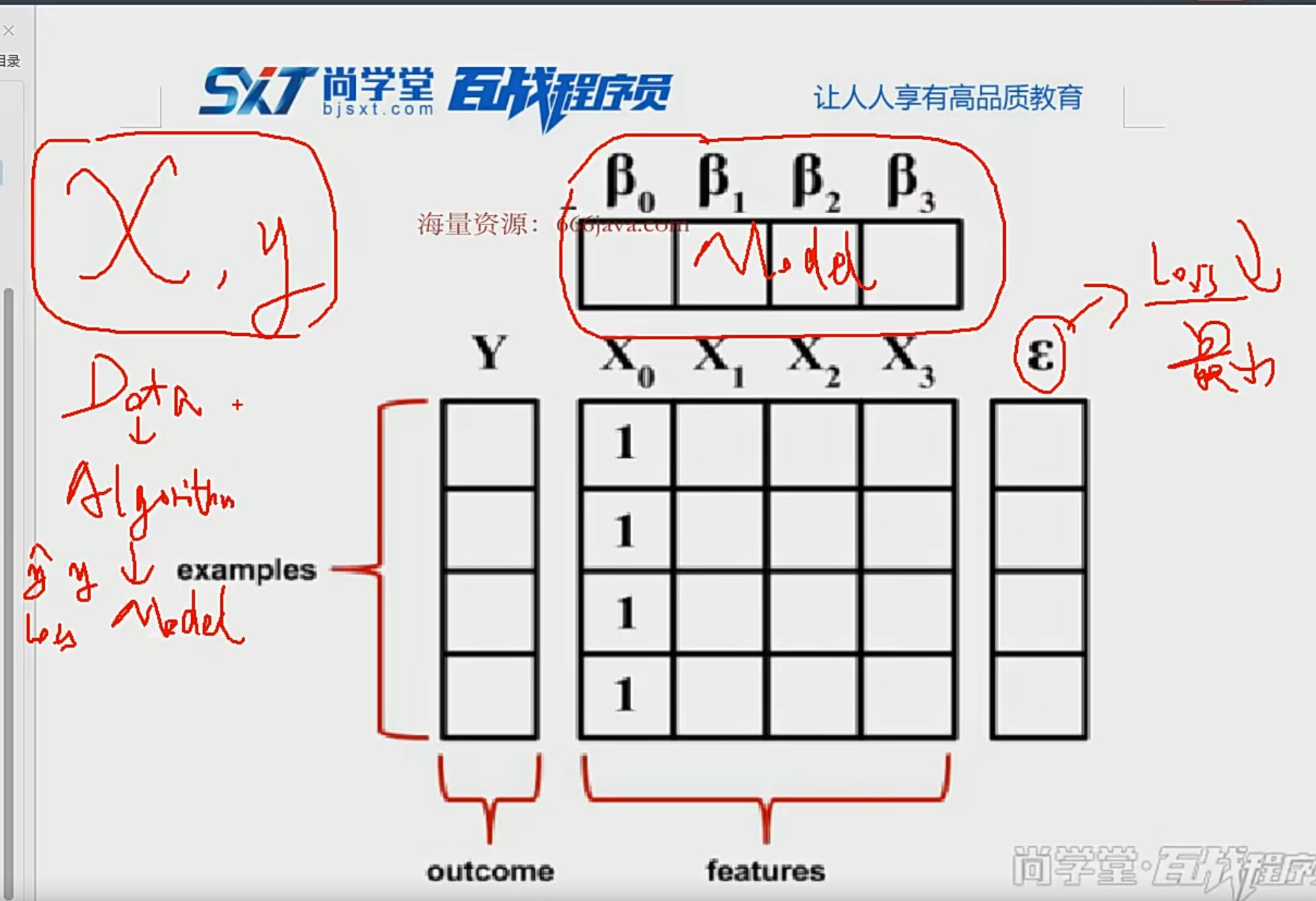
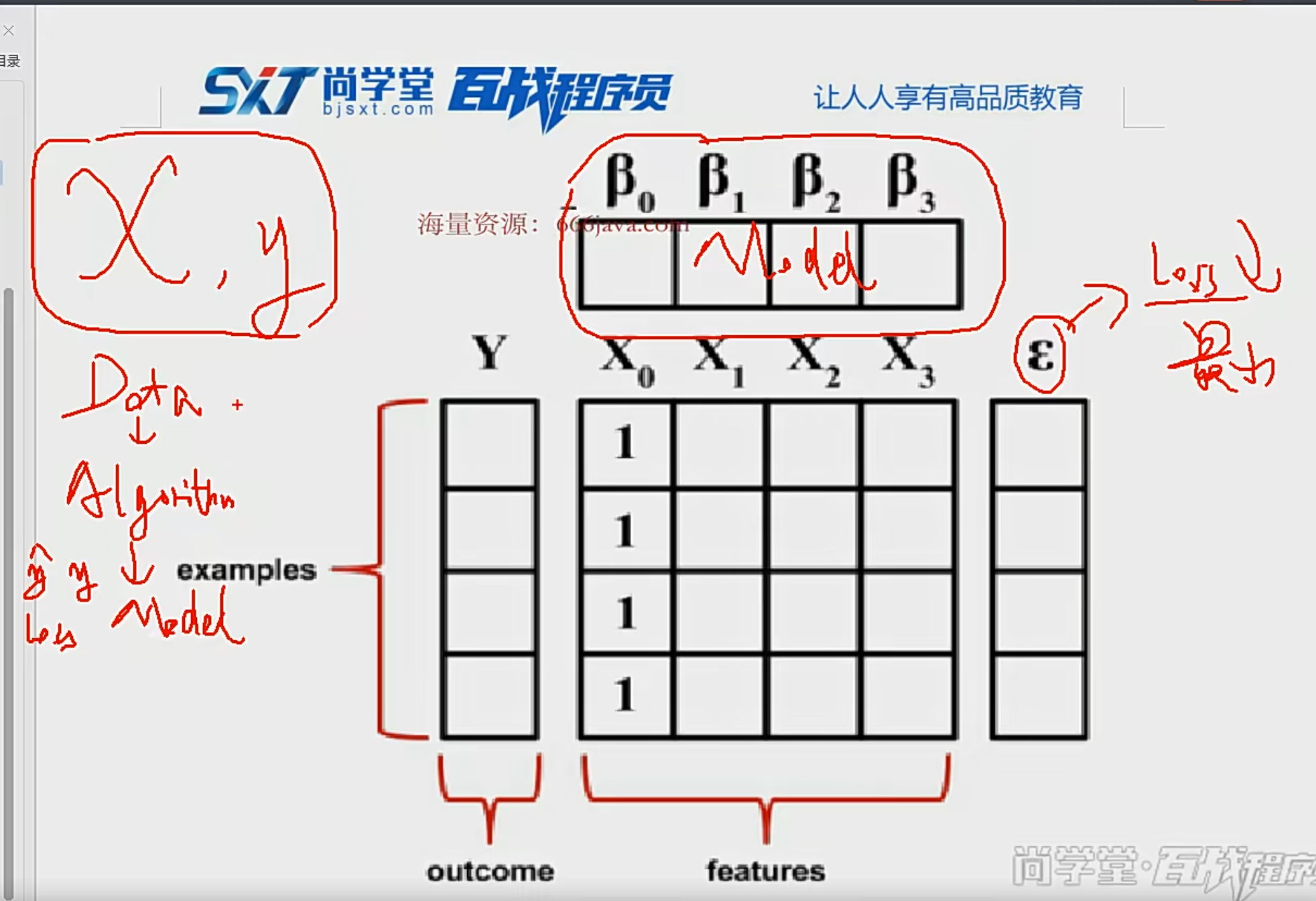
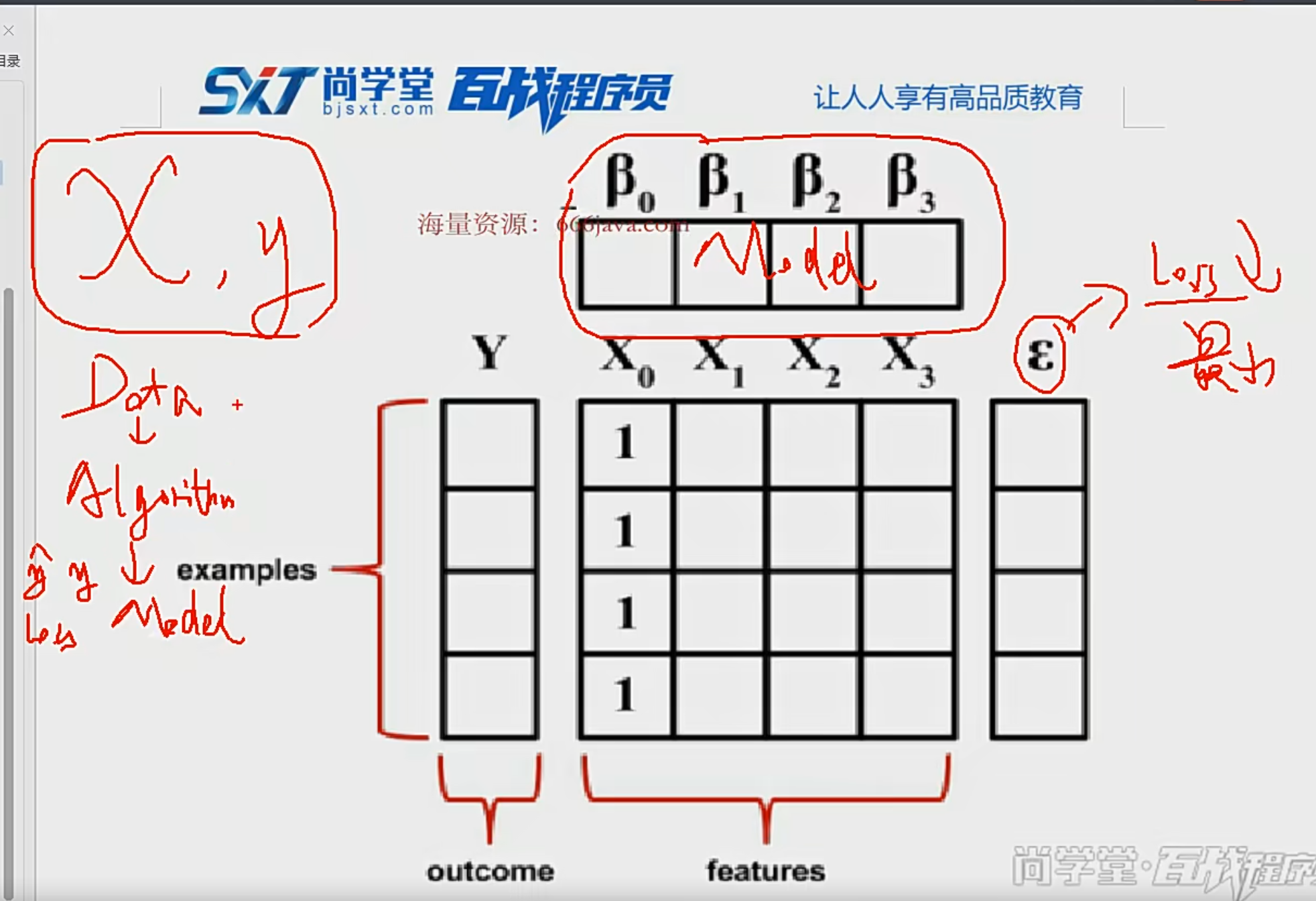
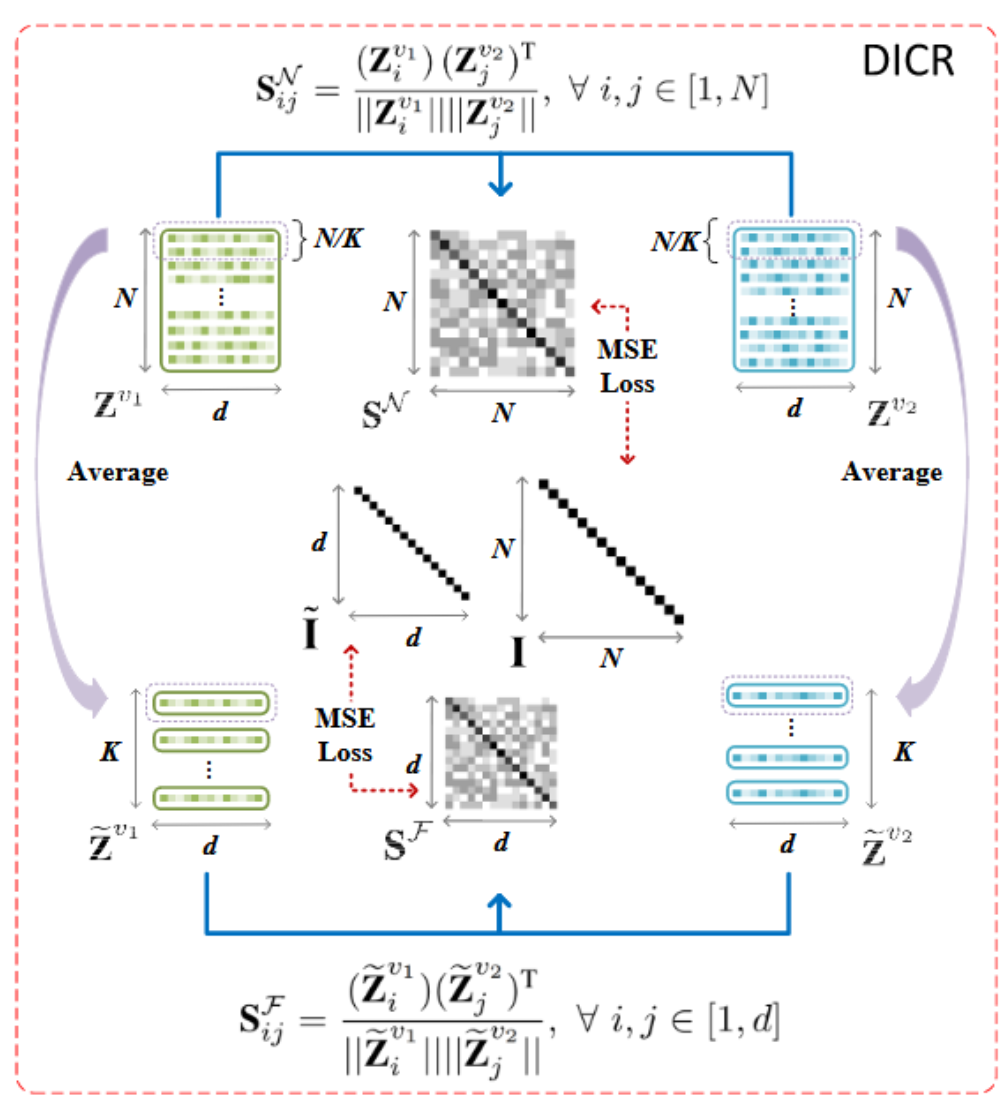
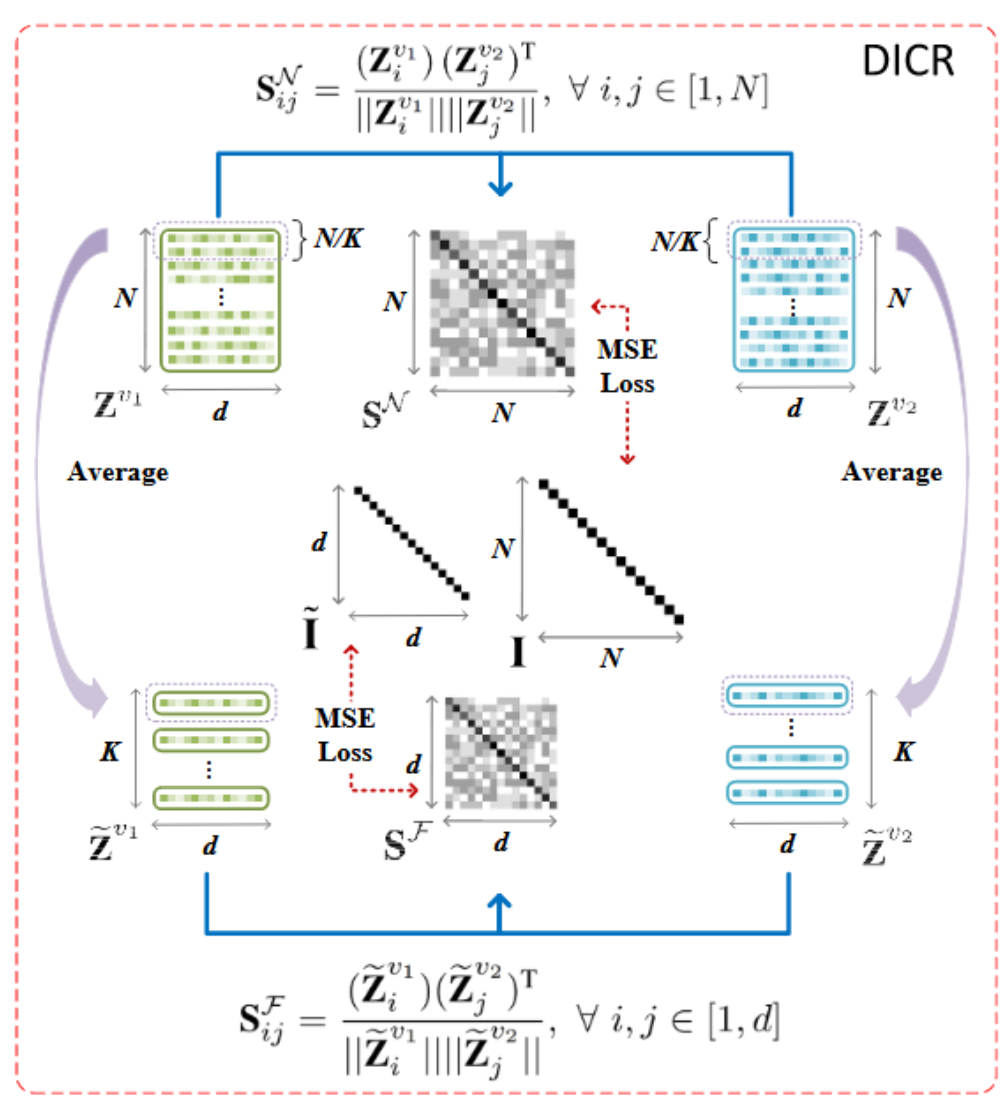
聚类损失为:换句话说,使得cluster的标签尽量和真实的标签(
我们使用双softmax函数来计算
第三部分:
可靠伪标签
我们选择样本
联合训练
我们将做如此预测: